PREVIOUS
StatREC
HEDNO Oracle - M.Sc Thesis
Aristotle University of Thessaloniki, Computer Science Department/Informatics
HEDNO Oracle is a programme developed in conjunction with my Master’s thesis “Machine learning methods for the analysis of data of an Electricity Distribution Network Operator”.
Download the Thesis Document: MS Word (docx), Adobe Acrobat (pdf)
Download the Presentation Document: MS PowerPoint (pptx), Adobe Acrobat (pdf)
The Thesis Committee was comprised by the:
Supervisor:
Dr. Eleftherios Angelis
Members:
Dr. Grigorios Tsoumakas
Dr. Ioannis Vlahavas
Description
HEDNO Oracle is based on the conceptual idea of Machine Learning.
It uses algorithms from unsupervised and supervised paradigms to forecast whether or not a given set of projects are going to be approved. To cluster the data, k-means is employed as per the former paradigm, whilst a plethora of different classification algorithms are used from the latter one. For optimal speed and scaling capabilities, the methods used and the source code as a whole are written in a manner suitable for Big Data. Technologies used include the SQL Server for relational database, the R Language for Mechanical Learning, the Microsoft ScaleR for highly scalable implementation of machine learning algorithms, as well as for communication, retrieval, processing, and storage of data in a Multi-Threaded and concurrent manner, overcoming memory (RAM) and processor (CPU) limitations.
The programme is built on the dataset provided by the Hellenic Electricity Distribution Network Operator (HEDNO S.A.), the largest company for the operation, maintenance and development of the power distribution network in Greece.
Technologies Used
Dataset Statistics
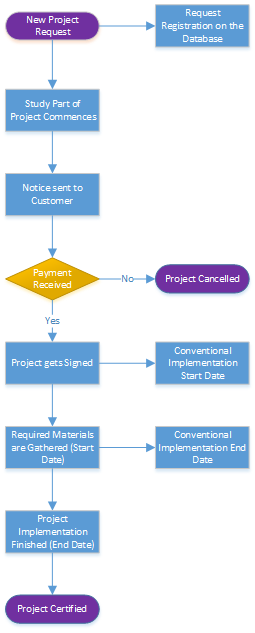
Project Timeline Flowchart
Procedure
The stages for a complete analysis, having connected to the SQL Server (something the programme handles itself), are the following:
Creating the Geolocation SQL Columns on the original Database to be filled at our convenience
Creating the SQL Views using multiple transformations to bring the data to a format usable by the programme
Using a Geolocation API to retrieve each project’s longitude and latitude
(Optional) Extracting the list of problematic addresses (those which failed) to replace them with addresses Google Maps can parse and re-geolocating to have 100% of projects’ longitudes and latitudes
Pre-processing the data to prepare them for clustering
Processing the data keeping only valid ones (for example, eliminating entries outside Greece’s region as invalid)
Performing Unsupervised learning
Forming the Train and Test sets
Performing Supervised Learning to predict the projects’ outcome using one of the 10 implementations
Supported Computing Contexts
Parallelism can be achieved by using each of the following contexts:
“RxLocalSeq” or “local” to execute the code from a local computer or laptop
“RxLocalParallel” or “localpar” to execute the code from a local computer in a parallel manner using the back-end for HPC computations, which is only used to distribute computations via the rxExec function
“RxSpark” or “spark” to connect to an Apache Spark general engine for large-scale data processing.
“RxHadoopMR” or “hadoopmr” to execute the code from a Hadoop cluster.
“RxInSqlServer” or “sqlserver” to create a compute context for running RevoScaleR analyses inside Microsoft SQL Server.
“RxInTeradata” or “teradata” to create a compute context for running RevoScaleR analyses inside a Teradata database.
“RxForeachDoPar” or “dopar” to create a compute context object using the registered foreach parallel back end, which is only used to distribute computations via the rxExec function.
PREVIOUS
StatREC
Other Projects



